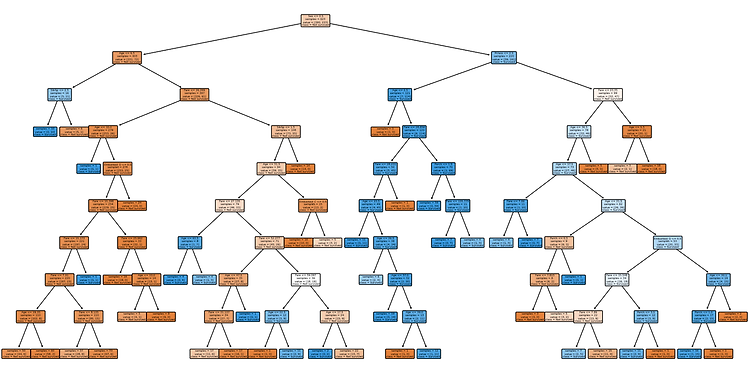
사설을 한번 시작하고 나니 멈출 수가 없습니다. 그렇지만 이것도 혼공단의 매력 아닐까 생각해 봅니다. 이번주는 정말 제 인생 그 어느 때보다 바빴다고 말할 수 있을 만큼 정신도 없고, 보람차기도 하고 피곤하기도 한 아무튼 그런 복잡한 한 주였는데 그 마무리를 혼공머신으로 할 수 있다니 감회가 남다릅니다. 트리 알고리즘, 결정 트리, Decision Tree 등 다양한 명칭으로 불리고 있는 이 알고리즘은 제가 전공 수업 때 직접 구현을 해본 모델이기도 합니다. 그래서 그런가요, 더 반가운 마음이 드네요. 바로 밑에 제가 구현했던 코드도 첨부해 놓았으니까요, 지루해질 때쯤 한번 구경해 보세요! 트리 알고리즘을 처음 구현하신 분들이라면 누구나 공감할 수 있는 웃픈 부분도 있으니까요🤣 그럼, 본격적으로 시작해 ..
무언가를 꾸준히 한다는 게 참 쉽지 않다는 걸 느끼고 있습니다. 왜 변환점을 도는 요맘때가 고비인 지 알 것 같아요 평일에 혼공단 활동을 하는 게 쉽지 않아서 주말에 하고 있는데 정말 하루하루가 순식간에 지나갑니다. 사설이 길어지는 3주차입니다..ㅎㅎ 진짜 그러면 시작해 볼까요!!! Ch 04-1. 로지스틱 회귀 ✔️ 로지스틱 회귀 : 선형 방정식을 바탕으로 분류를 하는 모델 시그모이드 함수를 이용하여 0~1 사이 값을 표현 - 넘파이를 이용하여 시그모이드 함수 그래프를 그리면 다음과 같다. ✔️ 로지스틱 회귀 이진 분류 실습 1) 데이터 준비 2) 모델 학습 3) 샘플 예측 및 예측 확률 출력 4) 사용된 로지스틱 회귀 함수 확인 따라서, 로지스틱 회귀 모델이 학습한 방정식은 다음과 같음 z = -0...
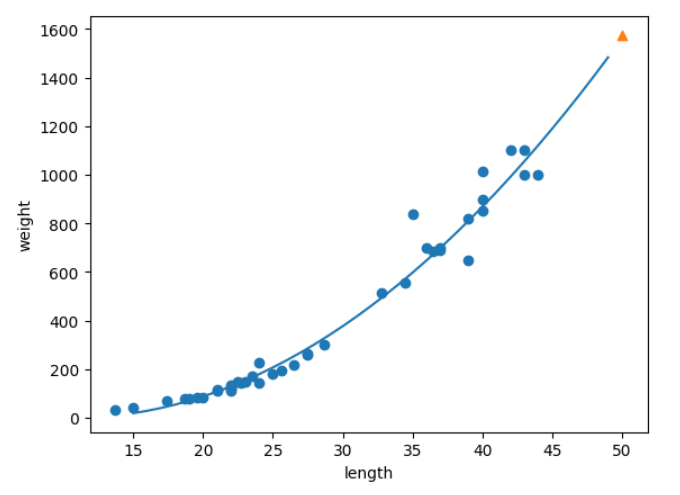
Ch 03-1. k-최근접 이웃 회귀 ✔️ 회귀 : 임의의 어떤 숫자를 예측하는 문제. 정해진 클래스가 없고 임의의 수치를 출력 ex) 내년도 경제 성장률 예측, 배달이 도착할 시간 예측 ✔️ k-최근접 이웃 회귀 : 분류와 똑같이 예측하려는 샘플에 가장 가까운 샘플 k개를 선택, k개의 평균값이 샘플의 예측 타깃값 : 이웃한 샘플의 타깃은 임의의 수치(not 클래스) ✔️ 교재 실습 1) 데이터 준비 및 시각화 2) 회귀 모델 훈련 및 평가 결정계수(R2) : 각 샘플의 타깃과 예측한 값의 차이를 곱하여 더하고, 타깃과 타깃 평균의 차이를 제곱하여 더한 값으로 나눔 : 타깃의 평균 정도를 예측하는 수준이라면 R2는 0에 가까워지고 예측이 타깃에 아주 가까워지면 1에 가까운 값이 됨 MAE(M..
Ch 02-1. 훈련 세트와 테스트 세트 ✔️ 지도 학습과 비지도 학습 - 지도 학습 : training data (input+target) 이 필요, input의 feature가 사용됨 → 알고리즘은 training data를 이용하여 정답을 맞히는 것을 학습(ex: binary classification) - 비지도 학습 : target 없이 input만 사용하여 학습 → 데이터 파악 및 변형에 이용 (+) 강화 학습 : target 없이 알고리즘이 행동한 결과로 얻은 보상을 사용해 학습 ✔️ 훈련 세트와 테스트 세트 - 훈련 세트: 훈련에 사용되는 데이터 - 테스트 세트: 평가에 사용하는 데이터 ⇒ 정확한 평가를 위해서는 훈련세트와 테스트 세트가 따로 준비되어야 함 ✔️ 샘플링 편향 : 훈련 세트와..