
Ch 02-1. 훈련 세트와 테스트 세트
✔️ 지도 학습과 비지도 학습
- 지도 학습
: training data (input+target) 이 필요, input의 feature가 사용됨
→ 알고리즘은 training data를 이용하여 정답을 맞히는 것을 학습(ex: binary classification)
- 비지도 학습
: target 없이 input만 사용하여 학습
→ 데이터 파악 및 변형에 이용
(+) 강화 학습
: target 없이 알고리즘이 행동한 결과로 얻은 보상을 사용해 학습
✔️ 훈련 세트와 테스트 세트
- 훈련 세트: 훈련에 사용되는 데이터
- 테스트 세트: 평가에 사용하는 데이터
⇒ 정확한 평가를 위해서는 훈련세트와 테스트 세트가 따로 준비되어야 함
✔️ 샘플링 편향
: 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않은 경우 발생
샘플링 편향이 과도할 경우, 제대로 된 지도 학습 모델을 만들 수 없음
✔️ 두 번째 머신러닝 프로그램
1. 샘플링 편향의 경우
1) 데이터 준비
2) 훈련 세트, 테스트 세트 나누기

3) 모델 학습 및 평가

2. 데이터를 무작위로 생성한 경우
1) 넘파이를 이용하여 데이터 셔플

2) 훈련 세트와 테스트 세트 준비


3) 새로운 훈련 세트, 테스트 세트로 학습

Ch 02-2. 데이터 전처리
✔️ 실습 - 데이터 전처리를 하지 않은 경우
1) 데이터 준비(numpy 이용)
- column_stack(): 전달받은 리스트를 일렬로 세운 다음 차례대로 나란히 연결


- concatenate(): 첫 번째 차원을 따라 배열을 연결, 연결할 리스트나 배열을 튜플로 전달
- ones() / zeros(): 각각 1과 0을 채운 배열을 생성

2) 훈련 세트와 테스트 세트 나누기(사이킷런 이용)
- train_test_split(): 전달되는 리스트나 배열을 비율에 맞게 훈련 세트와 테스트 세트로 나누어 줌
(+) 섞는 것도 포함. random_state 매개변수 지정 가능

- train_test_split()의 매개변수 stratify: 클래스 비율에 맞게 데이터 나눔(데이터가 작을 때 유용)

3) 모델 훈련 및 평가

4) 오류 발생 확인 : 도미가 아닌, 빙어로 분류

5) 오류 발생 이유 찾기
- kneighbors(): 이웃까지의 거리와 이웃 샘플의 인덱스를 반환


6) 오류 수정하기
- 오류의 원인: x축과 y축 간의 범위 불일치
- 오류 수정: matplotlib에서 xlim()을 이용하여 x축 범위 지정(cf. y축 범위는 ylim() )

✔️ 실습 - 데이터 전처리를 한 경우
데이터 전처리(data preprocessing)
: 데이터 특성 간의 scale이 다를 경우 특성값을 일정한 기준으로 맞춰주는 작업
- 표준점수(standard score, z score) : 가장 널리 사용하는 전처리 방법. 각 데이터가 원점에서 몇 표준편차만큼 떨어져 있는지를 나타냄

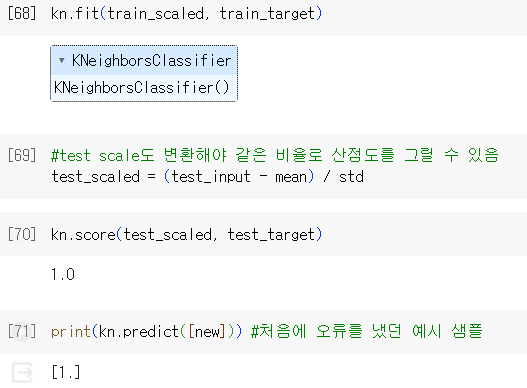
1) 전처리 데이터로 모델 훈련하기
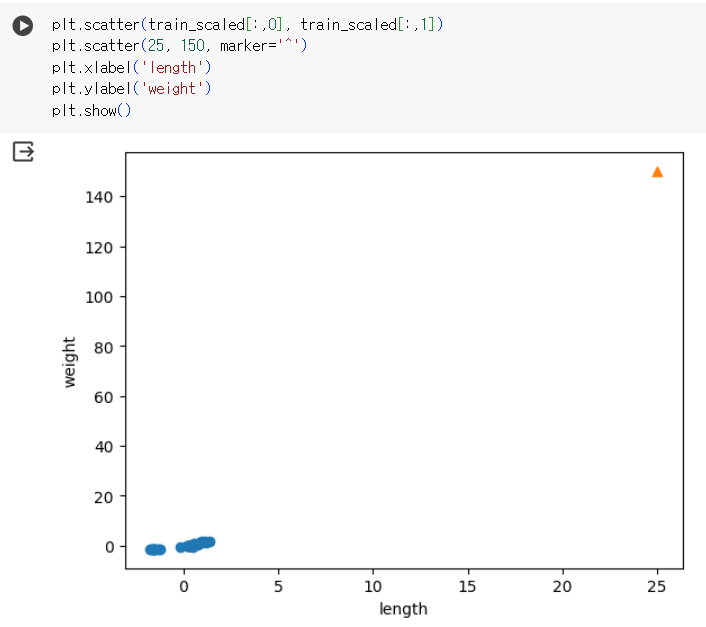

2) 결과

'Activities > [혼공단 11기] 머신러닝+딥러닝' 카테고리의 다른 글
| 5주차_Ch.06 비지도 학습 (0) | 2024.02.04 |
|---|---|
| 4주차_Ch.05 트리 알고리즘 (3) | 2024.01.28 |
| 3주차_Ch.04 다양한 분류 알고리즘 (5) | 2024.01.21 |
| 2주차_ Ch.03 회귀 알고리즘과 모델 규제 (1) | 2024.01.14 |
| 1주차_Ch.01 나의 첫 머신러닝 (6) | 2024.01.02 |