
Ch 01-1. 인공지능과 머신러닝, 딥러닝
✔️ 인공지능이란
: 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
| 강인공지능 (= 인공일반지능) | 약인공지능 |
| 영화 속 인공지능 ex) 영화 <그녀>의 사만다, <터미너이터>의 스카이넷 등 |
현실에서 마주하는 인공지능. 보조 역할만 가능 ex) 음성 비서, 자율 주행 자동차, 음악 추천, 기계 번역 등 |
✔️ 머신러닝이란
: 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 통계학과 관련이 높음(feat. 오픈소스 통계 소프트웨어 R)
- 최근 머신러닝은 경험을 바탕으로 발전
⇒ 대표적인 머신러닝 라이브러리: scikit-learn
- 파이썬 API 사용
- 오픈소스 라이브러리
✔️ 딥러닝이란
: 인공 신경망을 기반으로 한 방법들을 통칭
ex) LeNet-5, AlexNet 등
- 대표적인 라이브러리: TensorFlow(Google, 2015), PyTorch(FaceBook, 2018) ⇐ 모두 파이썬 API 제공
Ch 01-2. 코랩과 주피터 노트북
✔️ 구글 코랩
: 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스
(=클라우드 기반의 주피터 노트북 개발 환경)
✔️ 노트북
: 코랩 파일
- 구글 클라우드의 가상 서버 사용
- 동시에 사용할 수 있는 가상 서버는 최대 5개
- 1개의 노트북을 12시간 이상 실행 불가
✔️ 코랩 실습
- Hello World 출력 및 파일 이름 변경
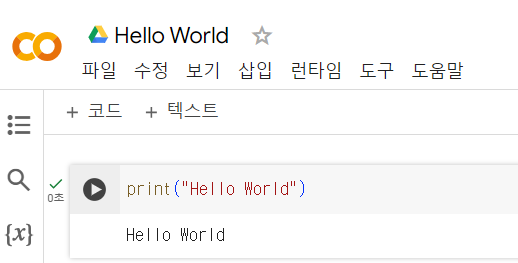
- 파일 변경 후 드라이브에서도 변경 확인 가능

Ch 01-3. 마켓과 머신러닝
✔️ 데이터 준비하기
 |
 |
도미 데이터(좌) 빙어 데이터(우)
✔️ 첫번째 머신러닝 프로그램
: k-Nearest Neighbors(k-최근접 이웃) 알고리즘 이용
1) 두 리스트를 하나로 합친 후 scikit-learn을 이용하기 위해 2차원 리스트로 변환

2) 정답 데이터 준비 : 규칙 찾기를 할 때 정답을 알려주어야 의미가 있음

3) 사이킷런 패키지에서 KNeighborsClassifier import

4) fish_data, fish_target 전달하여 훈련
- fit() 메서드: 주어진 데이터로 알고리즘 훈련
- score() 메서드: 모델을 평가, 0~1 사이 값 반환(1에 가까울수록 많은 데이터를 정확히 맞혔다는 것을 의미)

✔️ k-최근접 이웃 알고리즘
: 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용
⇒ 가장 가까운 직선거리에 있는 데이터를 보고 판단
⇔ 단점: 데이터가 아주 많으면 사용하기 어려움 (많은 메모리 차지, 시간 오래 걸림)
- predict() 메서드: 새로운 데이터의 정답 예측, 2차원 리스트 전달해야 함
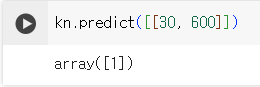
- kn._fit_X: fish data 속성

- kn._y: fish_target 속성

- 매개변수 n_neighbors를 변경하여 몇 개의 데이터를 참고할지 정할 수 있음

'Activities > [혼공단 11기] 머신러닝+딥러닝' 카테고리의 다른 글
| 5주차_Ch.06 비지도 학습 (0) | 2024.02.04 |
|---|---|
| 4주차_Ch.05 트리 알고리즘 (3) | 2024.01.28 |
| 3주차_Ch.04 다양한 분류 알고리즘 (5) | 2024.01.21 |
| 2주차_ Ch.03 회귀 알고리즘과 모델 규제 (1) | 2024.01.14 |
| 1주차_Ch.02 데이터 다루기 (2) | 2024.01.02 |