사설을 한번 시작하고 나니 멈출 수가 없습니다. 그렇지만 이것도 혼공단의 매력 아닐까 생각해 봅니다.
이번주는 정말 제 인생 그 어느 때보다 바빴다고 말할 수 있을 만큼 정신도 없고, 보람차기도 하고 피곤하기도 한 아무튼 그런 복잡한 한 주였는데 그 마무리를 혼공머신으로 할 수 있다니 감회가 남다릅니다.
트리 알고리즘, 결정 트리, Decision Tree 등 다양한 명칭으로 불리고 있는 이 알고리즘은 제가 전공 수업 때 직접 구현을 해본 모델이기도 합니다. 그래서 그런가요, 더 반가운 마음이 드네요. 바로 밑에 제가 구현했던 코드도 첨부해 놓았으니까요, 지루해질 때쯤 한번 구경해 보세요! 트리 알고리즘을 처음 구현하신 분들이라면 누구나 공감할 수 있는 웃픈 부분도 있으니까요🤣
그럼, 본격적으로 시작해 볼까요!
Ch 05-1. 결정 트리
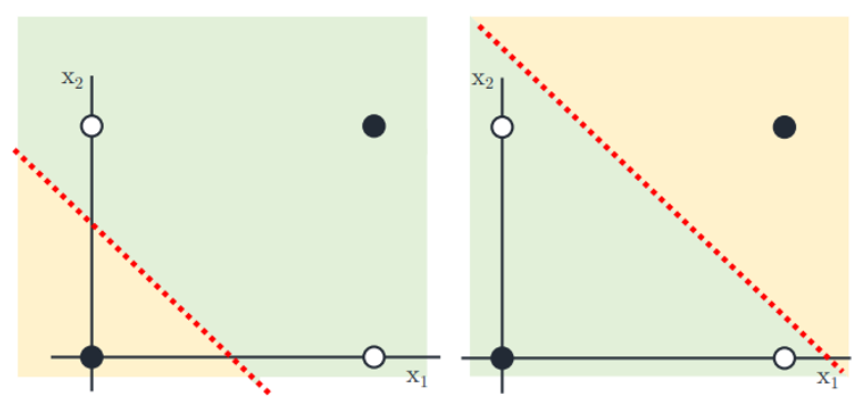
위의 그림은 Logestic Regression의 XOR 문제이다. 선형 분류 모델로만 나누게 된다면 다음과 같은 문제가 생김. (어느 방향으로 선을 그어도 똑바로 분류를 못함) 그래서 대안으로 나오게 된 것이 바로 Decision Tree임.
✔️ 결정 트리 실습
오늘은 먼저 실습부터 정리했다. 결과를 본 뒤에 설명하는 것이 더 효과적일 것 같아서!
1) 데이터 준비 및 로지스틱 회귀 학습 (더 보려면 펼치기!)
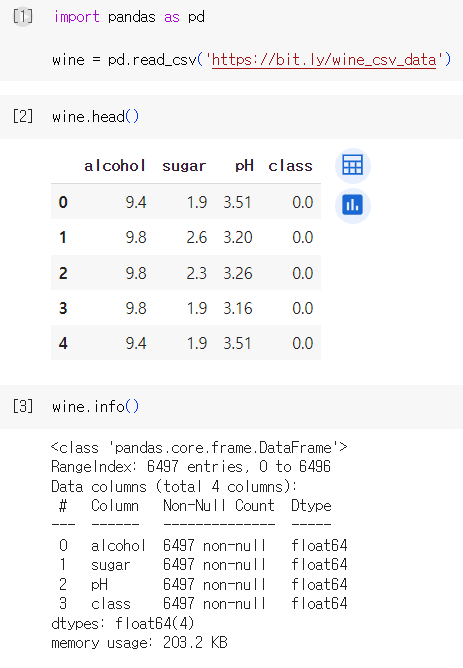



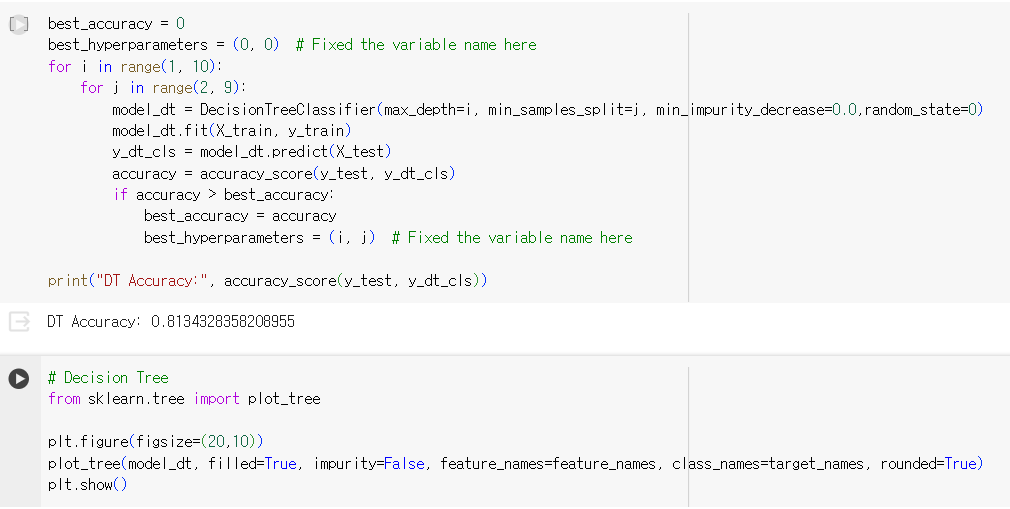
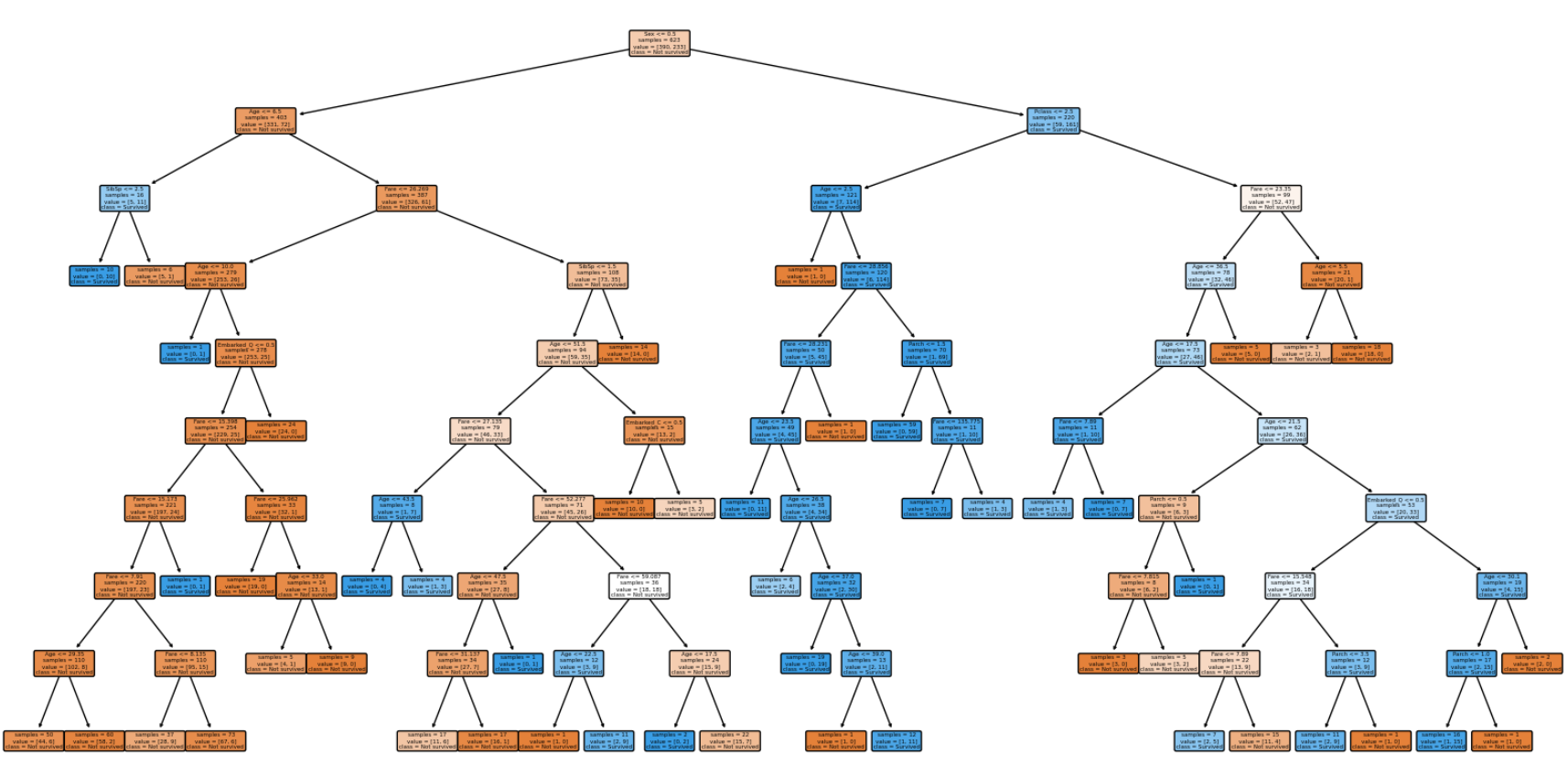
2) 결정 트리 모델 학습 및 결과 확인


✔️ 결정 트리
: 데이터를 잘 나눌 수 있는 질문을 추가하여 분류 정확도를 높이는 모델
사용법은 이전과 동일. fit()로 훈련 → score()로 정확도 평가
※ 결정 트리는 표준화 전처리 과정이 필요 없음. 다만 전처리를 하면 특성값을 표준점수로 바꾸지 않아 이해하기 더 쉬울 수 있음
🌳 결정 트리의 구조
- 노드(node): 결정 트리를 구성하는 핵심 요소. 훈련 데이터의 특성에 대한 테스트를 표현. 일반적으로 하나의 노드는 2개의 가지를 가짐
- 루트 노드(root node): 가장 위에 있는 노드(한 개)
- 리프 노드(leaf node): 가장 아래에 달린 노드(여러 개)
- 부모 노드(parent node): 주어진 노드의 상위 노드
- 자식 노드(child node): 하나의 노드로부터 분리되어 나간 2개 이상의 노드들 → 자신이 부모이자 자식 노드일 수 있음
- 가지(branch): 테스트의 결과(True, False)를 나타냄
🌳 결정 트리 예측 방법
: 리프 노트에서 가장 많은 클래스가 예측 클래스가 됨 (k -최근접 이웃과 유사)
🌳 불순도
- Gini impurity(지니 불순도) = $1 - (음성 클래스 비율^2 + 양성 클래스 비율^2)$
- Entropy(엔트로피) = $- 음성 클래스 비율 × log_2(음성 클래스 비율)$ $- 양성 클래스 비율 × log_2(양성 클래스 비율)$
 |
 |
⇒ 결정 트리 모델은 부모 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장시킴
= 정보 이득이 최대가 되도록 데이터를 나눔
🌳 가지치기(Pruning)
: 일반화가 잘 될 수 있도록(=과대적합이 되지 않도록) 트리를 조절하는 것. 가장 대표적인 방법은 트리의 최대 깊이를 지정하는 것임 → max_depth 매개변수 지정
✔️ 결정 트리 다시 실습해 보기

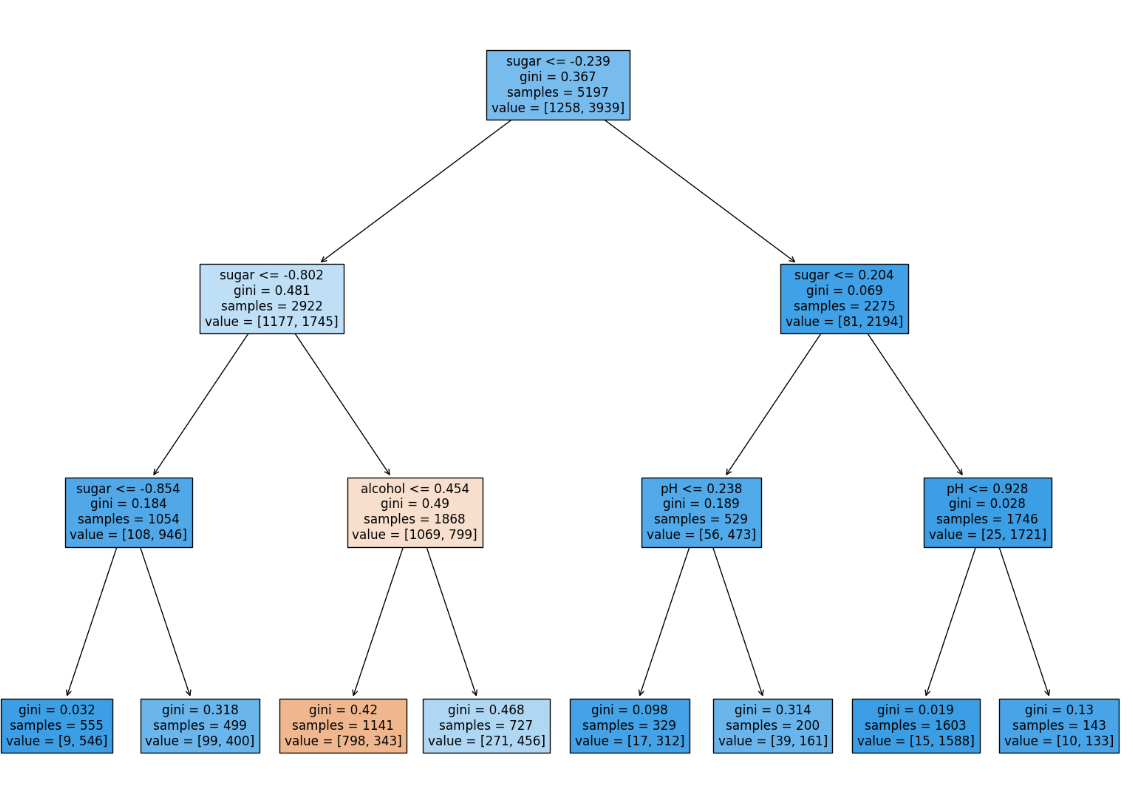
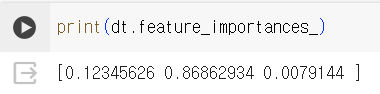
- 특성 중요도 계산
- 특성 중요도 : 각 노드의 정보 이득과 전체 샘플에 대한 비율을 곱한 후 특성별로 더하여 계산함. 특성 중요도의 값을 모두 더하면 1이 됨.
특성 중요도는 결정 트리 모델을 특성 선택에 활용할 수 있게 해 줌.
Ch 05-2. 교차 검증과 그리드 서치
✔️ 검증 세트(validation set)
: 훈련 세트를 나누어 모델이 과대적합인지 과소적합인지 측정하는 세트
- 실습

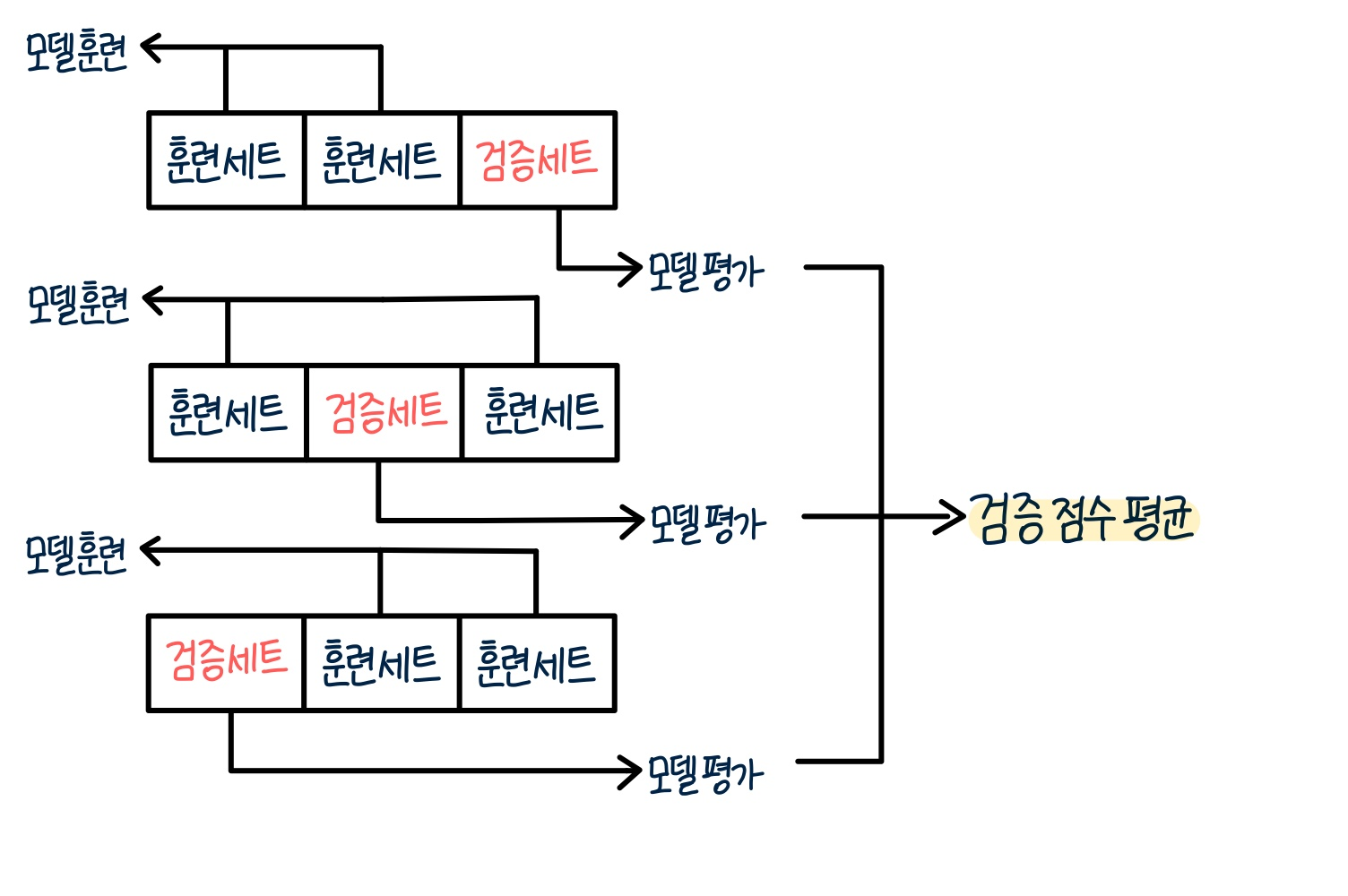
✔️ 교차 검증 (cross validation)
: 검증 세트를 떼어 내어 평가하는 과정을 여러 번 반복하고, 그 점수를 평균하여 최종 검증 점수를 얻음
k-fold cross validation이라고 부르며, k에 몇 부분으로 나누는지에 따라 2-fold, 3-fold 등 다양하게 통칭할 수 있음.
교차 검증을 이용하면 데이터의 80% ~ 90%까지 훈련에 사용할 수 있음
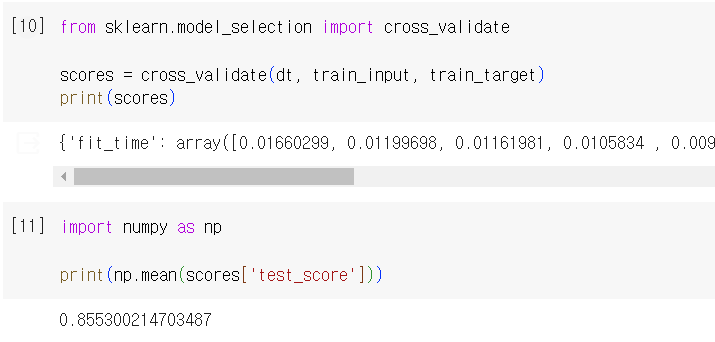
- 실습
- cross_validate() 이용. fit_time, score_time, test_score 키를 가진 딕셔너리를 반환함
cf. cross_val_score()는 cross_validate()의 전신으로 test_score값만 반환함


✔️ 하이퍼파라미터 튜닝
- 하이퍼파라미터: 모델이 학습할 수 없어서 사용자가 지정해야만 하는 파라미터
- 하이퍼파라미터 튜닝: 라이브러리가 제공하는 기본값을 그대로 사용해 모델을 훈련한 후, 검증 세트의 점수나 교차 검증을 통해 매개변수를 조금씩 바꿔나감.
※ 하나의 파라미터가 바뀌면 다른 매개변수의 최적값이 바뀜 → 두 매개변수를 동시에 바꿔가며 최저의 값을 찾아야 함
- GridSearchCV: 하이퍼파라미터 탐색과 교차 검증을 한 번에 수행. 최상의 모델을 찾은 후 훈련 세트를 전체로 사용해 최종 모델을 훈련
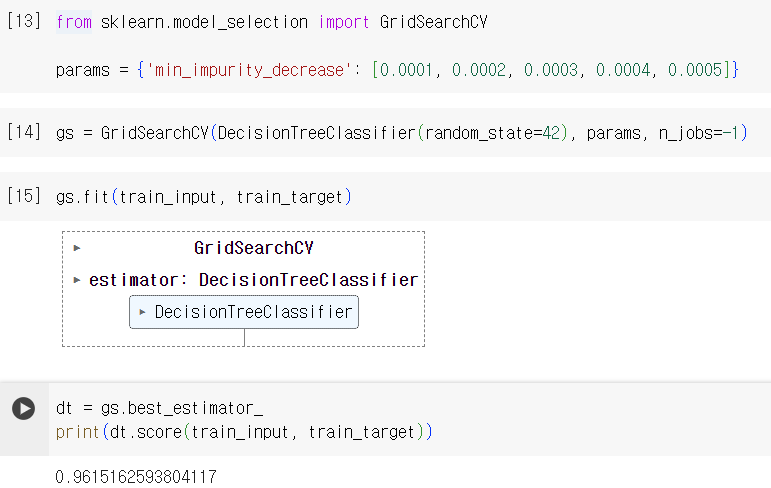

- GridSearchCV 과정 정리
- 탐색할 매개변수 지정
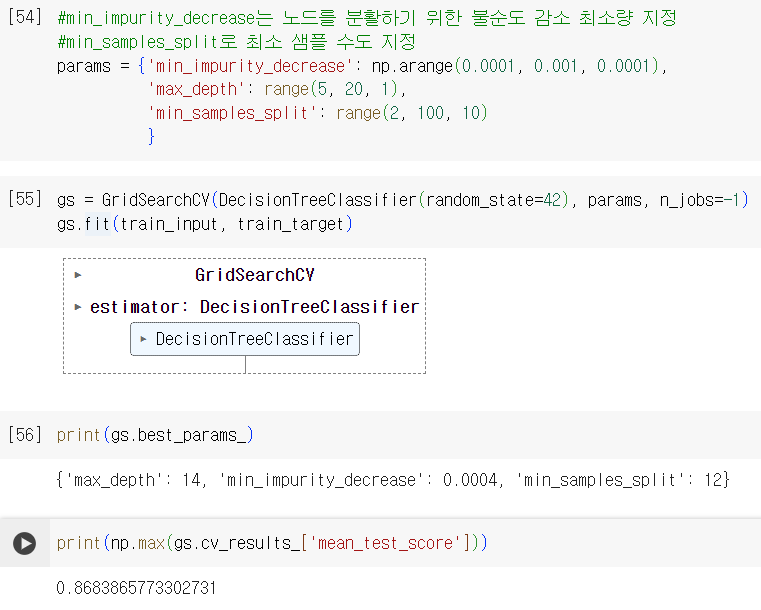
- 훈련 세트에서 그리드 서치를 수행하여 최상의 평균 검증 점수가 나오는 매개변수 조합을 찾는다
- 그리드 서치는 최상의 매개변수에서 전체 훈련 세트를 사용해 최종 모델을 훈련. 이 모델도 그리드 서치 객체에 저장
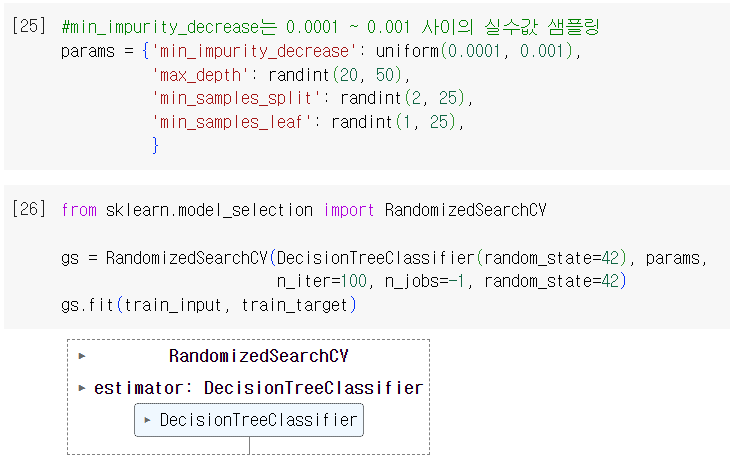
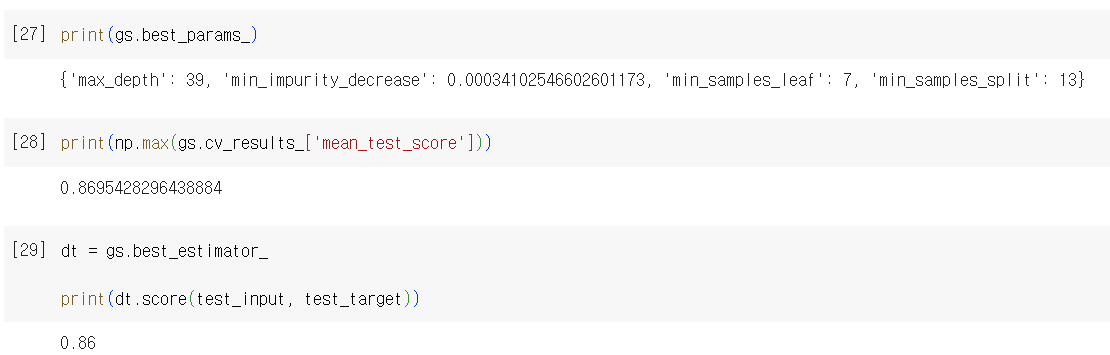
- Random Search: 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달

Ch 05-3. 트리의 앙상블
✔️ 랜덤 포레스트(Random Forest)
: 앙상블 학습의 대표 주자 중 하나로, 결정 트리를 랜덤 하게 만들어 결정 트리(나무)의 숲을 만듦.
⇒ 각 결정 트리의 예측을 사용해 최종 예측을 만듦
- 데이터 생성(=부트스트랩 샘플) : 훈련 데이터에서 랜덤하게 샘플을 추출, 이때 한 샘플이 중복되어 추출될 수 있음
- 각 노드 분할: 전체 특성 중 일부 특성을 무작위로 고른 다음, 이 중에서 최선의 분할을 찾음
- RandomForestClassifier: 전체 특성 개수의 제곱근만큼의 특성 선택 → 각 트리의 클래스별 확률을 평균하여 가장 높은 클래스를 예측으로 삼음
- RandomForestRegression: 전체 특성 사용 → 각 트리의 예측을 평균
- OOB 샘플: 부트스트랩 샘플에 포함되지 않고 남는 샘플 ← 부트스트랩 샘플로 훈련한 결정 트리를 평가하는 데 이용가능
➡️ 훈련 세트에 과대적합되는 것을 방지(∵ 랜덤하게 선택한 샘플과 특성 사용) ⇒ 검증 세트와 테스트 세트에서 안정적인 성능을 얻을 수 있음
- 실습

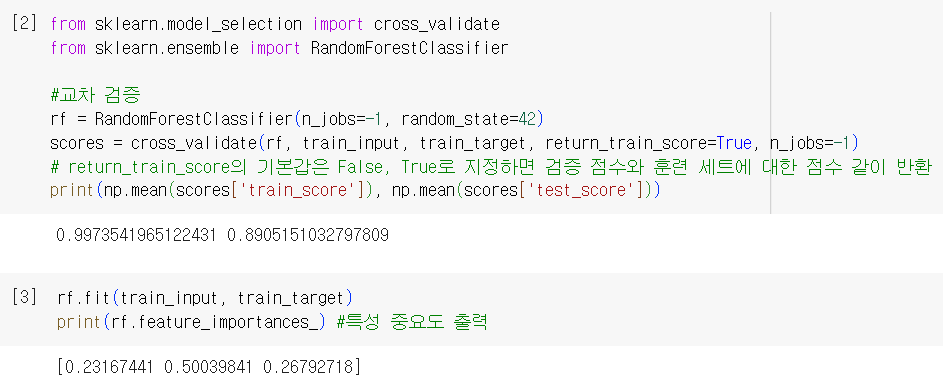

✔️ 엑스트라 트리 (Extra Trees)
: 랜덤 포레스트와 매우 유사, 기본적으로 100개의 결정 트리 훈련
- 전체 특성 중 일부 특성을 랜덤하게 선택하여 노드를 분할하는 데 사용
⚠️ 랜덤 포레스트와 엑스트라 트리의 차이점: 부트스트랩 샘플을 사용하지 않음(= 결정 트리를 만들 때 전체 훈련 세트 사용), 노드 분할 시 무작위로 분할
splitter = 'random'
- 실습
✔️ 그레이디언트 부스팅 (=Gradient Boosting)
: 깊이가 얕은 결정 트리를 사용하여 이전 트리의 오차를 보완하는 방식으로 앙상블 하는 방법. 결정 트리를 계속 추가해 가면서 가장 낮은 곳을 찾아 이동
- 기본적으로 깊이가 3인 결정 트리를 100개 사용 ⇒ 과대 적합에 강하고, 높은 일반화 성능을 기대할 수 있음
- 경사 하강법을 사용하여 트리를 앙상블에 추가
- 분류: 로지스틱 손실 함수, 회귀: 평균 제곱 오차 함수 사용
- 학습률 매개변수로 속도 조절
- 실습



✔️ 히스토그램 기반 그레이디언트 부스팅 (= Histogram-based Gradient Boosting)
: 입력 특성을 256개 구간으로 나눔 → 노드를 분할할 때 최적의 분할을 매우 빠르게 찾을 수 있음
- 입력에 누락된 특성이 있더라도 따로 전처리할 필요가 없음
- 기본 매개별수에서 안정적인 성능을 얻을 수 있음
- 트리의 개수를 지정할 때 max_iter를 사용
- 실습

- permutation_importance(): 특성을 하나씩 랜덤 하게 섞어서 모델의 성능이 변화하는지를 관찰, 어떤 특성이 중요한 지 계산. 훈련 세트, 테스트 세트에 모두 적용 가능(+추정기 모델에도 사용 가능).
imporances(특성 중요도), importances_mean(평균), importances_std(표준편차) 반환


'Activities > [혼공단 11기] 머신러닝+딥러닝' 카테고리의 다른 글
| 6주차_Ch.07 딥러닝을 시작합니다 (0) | 2024.02.15 |
|---|---|
| 5주차_Ch.06 비지도 학습 (0) | 2024.02.04 |
| 3주차_Ch.04 다양한 분류 알고리즘 (5) | 2024.01.21 |
| 2주차_ Ch.03 회귀 알고리즘과 모델 규제 (1) | 2024.01.14 |
| 1주차_Ch.02 데이터 다루기 (2) | 2024.01.02 |